A Spectrum Evaluation Benchmark for Medical Multi-modal Large Language Models
Introduction
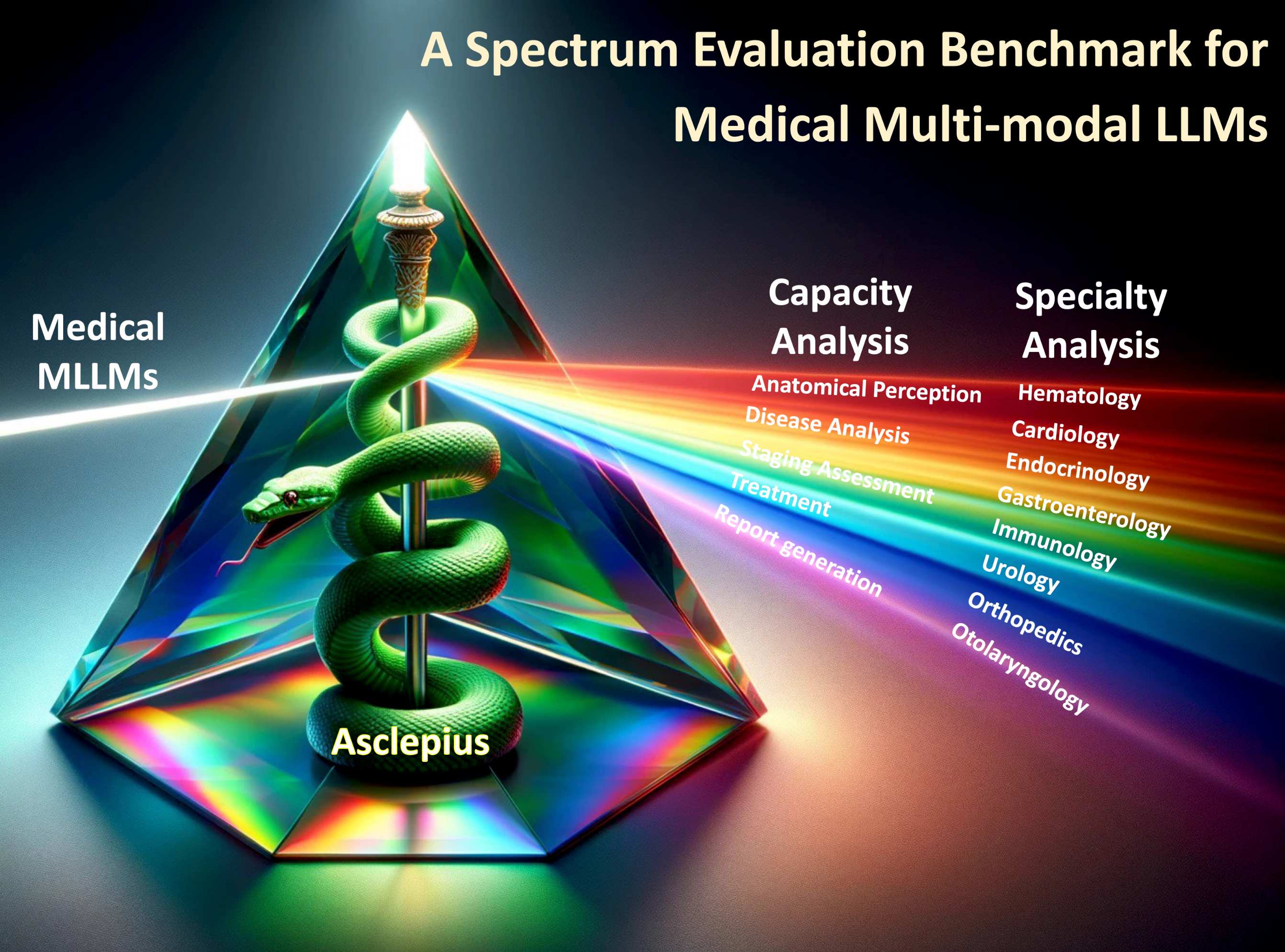
The burgeoning field of Medical Multi-modal Large Language Models (Med-MLLMs) has shown great potential in transforming healthcare through advanced decision support and information synthesis. However, these models are often evaluated using benchmarks ill-suited for the complexity of Med-MLLMs, as they typically neglect the assessment across diverse medical domains and complex clinical decisions. Moreover, these benchmarks are susceptible to data leakage, since Med-MLLMs are trained on large assemblies of publicly available data. To address these obstacles, we introduce Asclepius, a novel benchmark designed to rigorously assess the performance of Med-MLLMs across a range of medical specialties and clinical decision dimensions. Grounded in three core principles, Asclepius ensures a comprehensive evaluation by encompassing 15 medical specialties, stratifying into 3 main categories and 8 sub-categories of clinical tasks, and avoiding data contamination by using novel datasets. We further provide an in-depth analysis of six Med-MLLMs and compare them with human specialists, providing insights into their competencies and limitations in various medical contexts. Our work not only advances the understanding of Med-MLLMs' capabilities but also sets a precedent for future evaluations and the safe deployment of these models in clinical environments.